Près d’un site sur trois subit des pertes de trafic importantes à cause de textes identiques éparpillés sur plusieurs URL. Ce phénomène fragmente votre autorité et brouille les pistes pour les algorithmes de Google.
On finit souvent par voir ses meilleures pages disparaître des résultats de recherche au profit de doublons techniques. Nous avons conçu ce guide pour vous aider à déployer chaque solution contenu dupliqué afin de protéger durablement votre visibilité et votre PageRank.
Comprendre le contenu dupliqué et ses risques réels
Le contenu dupliqué (interne ou externe) fragmente l’autorité SEO et dilue le PageRank. Les solutions reposent sur l’usage de la balise canonical, des redirections 301 et une rédaction 100% unique pour protéger son indexation. Mais alors, comment distinguer un simple bug technique d’un véritable vol de propriété intellectuelle ?
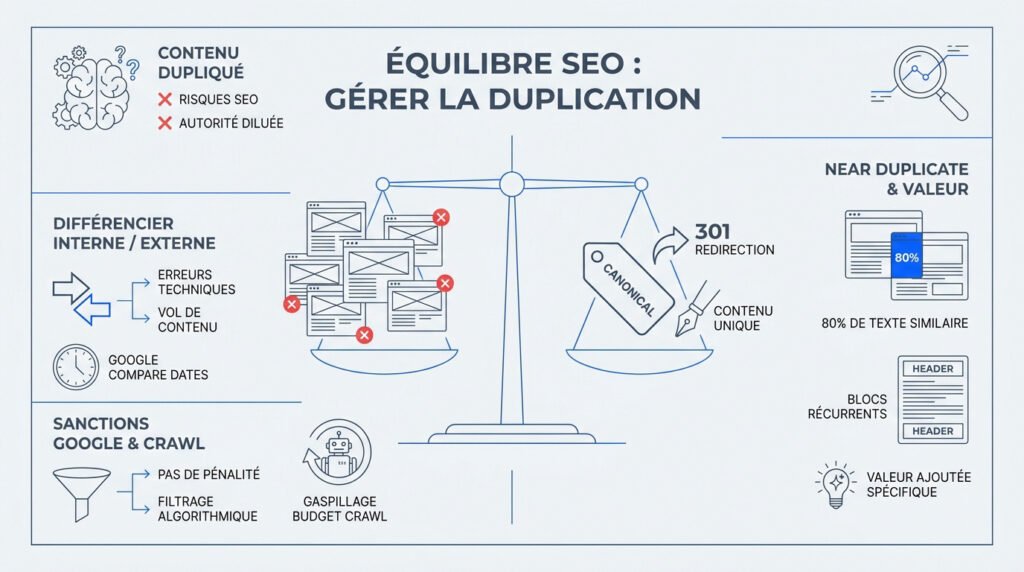
Différencier la duplication interne de la copie externe
La duplication interne surgit souvent de soucis techniques comme le conflit entre HTTP et HTTPS. À l’inverse, la version externe provient généralement d’un vol de contenu malveillant.
Google tente systématiquement de repérer l’émetteur initial du texte. Pour cela, il analyse précisément les dates de première indexation.
Certaines causes sont classiques, comme des URLs de test restées indexées par erreur. C’est un oubli fréquent lors des phases de déploiement technique.
Décrypter la réalité des sanctions de Google
Il n’existe pas de pénalité automatique mais plutôt un filtrage algorithmique. Google retient une seule version et écarte les autres. Votre trafic chute car vos pages sont simplement mises de côté.
Le vrai danger réside dans le gaspillage de votre budget de crawl. Le robot s’épuise sur des pages inutiles. Votre nouveau contenu met donc beaucoup plus de temps à être visible.
Identifier le contenu presque dupliqué ou near duplicate
On parle de near duplicate quand deux pages partagent environ 80% de texte. Ce cas est très courant sur les catalogues de produits similaires.
Les blocs récurrents comme les headers ou footers pèsent lourd. Trop de similitudes finissent par noyer le message principal et l’unicité de votre page.
Il faut donc injecter du contexte spécifique sur chaque URL. Cela permet aux algorithmes de percevoir immédiatement votre réelle valeur ajoutée.
Détecter les doublons avec une méthode d’audit fiable
Après avoir compris les risques, il est temps de passer à l’action en utilisant des outils de diagnostic précis pour scanner votre site.
Utiliser Screaming Frog et Siteliner pour l’audit interne
Configurez Screaming Frog pour analyser vos balises HTML. L’outil repère immédiatement les titres et descriptions identiques entre vos pages. C’est souvent le premier signe d’un problème structurel profond.
Utilisez ensuite Siteliner pour calculer votre similarité globale. Les zones rouges du rapport exigent une correction rapide. Vous identifierez ainsi les contenus qui se cannibalisent inutilement.
Identifiez enfin les erreurs de structure. Un mauvais code génère parfois des milliers d’URLs fantômes. Nettoyer ces scories techniques libère immédiatement votre budget de crawl.
Surveiller le vol de texte avec Copyscape et Killduplicate
Utilisez la recherche inverse pour débusquer les pilleurs de contenus. Vous pouvez vous appuyer sur des logiciels spécialisés comme Killer duplicate pour automatiser cette veille. Ne laissez plus personne voler votre expertise.
Paramétrez des alertes automatiques régulières. Protégez ainsi votre patrimoine éditorial. Il est hors de question de laisser les autres profiter de votre travail acharné.
Comparez les outils disponibles. Les versions payantes sont plus réactives. Elles offrent une protection robuste.
Exploiter la Search Console pour repérer les anomalies
Consultez régulièrement votre rapport de couverture. Cherchez spécifiquement les mentions excluant les doublons non choisis par Google. C’est ici que le moteur révèle ses propres arbitrages sur votre site.
Utilisez l’outil d’inspection d’URL pour chaque page suspecte. Vérifiez quelle version exacte Google a décidé de favoriser. Vous saurez alors si vos balises canoniques sont bien respectées.
Surveillez les pics d’indexation soudains. Une hausse anormale cache souvent des URLs dynamiques incontrôlées. Agissez vite pour éviter que ces pages inutiles ne polluent vos résultats.
Déployer les solutions techniques pour assainir vos pages
Une fois les doublons identifiés, vous devez appliquer les correctifs techniques appropriés pour reprendre le contrôle de votre indexation.
Installer la balise canonical comme signal prioritaire
La balise rel= »canonical » définit la page source. Elle indique officiellement la page maître parmi plusieurs variantes identiques. Pour un accompagnement expert, faites confiance à GK digital afin de sécuriser votre structure.
Placez ce tag dans la section head du HTML. Suivez ces conseils officiels pour la balise canonical pour garantir un paramétrage sans faille.
Bannissez les URLs relatives. Utilisez uniquement des chemins absolus. Vos robots d’exploration ne s’égareront plus.
Réussir ses redirections 301 sans perdre de trafic
Utilisez la redirection 301 pour fusionner deux contenus identiques. C’est la méthode la plus propre pour transférer l’autorité SEO accumulée. Le jus de lien circule ainsi vers l’URL unique.
Gérez vos migrations HTTP vers HTTPS avec précision. Assurez-vous que chaque ancienne page pointe vers son équivalent sécurisé. Vous maintenez ainsi votre visibilité sans aucune coupure pour vos visiteurs.
Adopter cette solution offre des bénéfices immédiats :
- Transfert de jus SEO efficace.
- Expérience utilisateur fluide.
- Suppression définitive du doublon.
Utiliser le noindex pour les pages sans valeur ajoutée
Identifiez les pages techniques comme les paniers ou les résultats de recherche interne. Ces pages ne doivent pas polluer l’index. Appliquez une balise meta noindex pour les garder accessibles sans les référencer. C’est simple et radical.
Faites bien la distinction avec le robots.txt. Le fichier robots empêche le crawl, mais pas forcément l’indexation. Le noindex reste l’arme absolue pour garantir l’absence totale d’une URL dans les résultats Google.
Résoudre les conflits d’URLs sur les sites complexes
Pour les sites e-commerce ou internationaux, les solutions classiques ne suffisent pas toujours face à la multiplication des paramètres d’URL.
Gérer la navigation à facettes et les paramètres dynamiques
Neutralisez la duplication induite par les filtres de prix ou de taille. Ces paramètres créent des milliers d’URLs inutiles. Ils gaspillent votre budget d’exploration.
Configurez la gestion des paramètres dans la Search Console. Indiquez à Google quels éléments ignorer lors du crawl. Cela protège votre indexation.
Appliquez des règles au niveau du serveur. Épurez les URLs avant leur découverte par les robots. Utilisez des fragments d’URL pour les filtres.
Traiter les fiches produits standardisées en e-commerce
Réécrivez les descriptions des marques. Il est vital de rédiger des descriptions uniques. Le copier-coller nuit gravement à votre autorité.
Regroupez les variantes sur une URL unique. Utilisez des sélecteurs JavaScript pour éviter de multiplier les pages. Votre structure sera plus saine.
| Type de page | Risque | Solution |
|---|---|---|
| Fiches constructeur | Très élevé | Contenu original |
| Catégories filtrées | Moyen | Canonical ou Noindex |
| Versions de test | Élevé | Robots.txt |
| Blogs syndiqués | Faible | Rel= »canonical » |
Harmoniser les versions internationales avec le hreflang
Utilisez les balises hreflang pour vos sites francophones. Cela évite que la France et la Belgique ne se concurrencent. L’internaute verra la version adaptée.
Vérifiez la réciprocité des liens. Chaque page doit pointer vers sa version alternative. Sans ce renvoi, Google ignorera vos déclarations linguistiques.
Configurez des URLs régionales précises. Un ciblage rigoureux garantit l’accès à la bonne version. Utilisez exclusivement des URLs absolues pour la clarté.
Anticiper les nouveaux défis liés à l’IA et au scraping
Enfin, l’émergence de l’IA générative et l’automatisation du scraping imposent de nouvelles stratégies pour protéger l’originalité de votre site.
Valoriser la création humaine face aux textes générés par IA
Google détecte de mieux en mieux les contenus produits en masse par IA. La similarité sémantique devient un critère de filtrage majeur. Vous devez donc surveiller la qualité de vos publications.
Intégrez des preuves d’expérience réelle (EEAT). Parlez de vos tests, de vos échecs et de vos réussites concrètes pour rester unique. Nous voyons que l’authenticité devient un levier de différenciation.
Renforcez votre signature éditoriale. Un ton humain et engagé est impossible à copier parfaitement par une machine. C’est votre meilleure protection.
Défendre son autorité face au pillage de contenu automatisé
Mettez en place des pare-feu contre les robots de scraping agressifs. Bloquez les adresses IP suspectes qui aspirent vos données en continu. Utilisez des CAPTCHA pour distinguer les humains des scripts.
Réagissez techniquement et juridiquement via des demandes DMCA. Ne laissez pas un site tiers se classer devant vous avec vos propres textes. Le scraping dilue la pertinence de votre marque.
Sécurisez vos flux RSS. Ne diffusez que des extraits pour forcer les pilleurs à ne récupérer que des bribes inutilisables. Cela préserve votre valeur ajoutée.
Améliorer le maillage interne pour stabiliser le PageRank
Structurez vos liens internes vers vos pages piliers. Cela clarifie la hiérarchie pour Google et renforce les contenus les plus importants. Une bonne architecture facilite l’exploration par les robots.
Évitez de lier systématiquement des pages trop proches sémantiquement. Cela crée une confusion sur la page qui doit réellement se positionner. Vous risquez de diluer votre autorité inutilement.
Voici quelques réflexes à adopter pour vos liens :
- Utiliser des ancres variées
- Prioriser les liens dans le corps du texte
- Limiter le nombre de liens par page
Protégez votre SEO en utilisant la balise canonical, les redirections 301 et une rédaction 100 % unique. Cette solution contenu dupliqué assainit votre indexation et restaure votre autorité immédiatement. Agissez dès maintenant pour transformer vos doublons en leviers de croissance et dominer durablement les résultats de recherche.
FAQ
Qu’est-ce que le duplicate content et pourquoi nuit-il à mon référencement ?
Le contenu dupliqué, ou duplicate content, désigne des blocs de texte identiques ou très similaires qui apparaissent sur plusieurs URLs différentes. Cette situation peut survenir au sein de votre propre site (duplication interne) ou entre plusieurs domaines distincts (duplication externe).
Pour les moteurs de recherche comme Google, cela crée une confusion algorithmique : ils peinent à identifier la version la plus pertinente à indexer. En conséquence, vos pages peuvent se concurrencer entre elles, diluer votre PageRank et entraîner une baisse significative de votre trafic organique.
Quelles sont les sanctions appliquées par Google en cas de contenu dupliqué ?
Contrairement à une idée reçue, il n’existe pas de « pénalité » automatique au sens strict, mais plutôt un filtrage algorithmique. Google choisit une seule version d’une page et ignore les autres, ce qui peut rendre vos contenus invisibles. Toutefois, si la duplication est jugée intentionnelle pour manipuler les résultats, les risques sont plus lourds : désindexation de pages, voire blacklistage complet du site.
Un autre impact majeur est le gaspillage de votre budget de crawl. Les robots perdent un temps précieux à analyser des doublons au lieu d’indexer vos nouveaux contenus stratégiques, ralentissant ainsi votre progression globale.
Comment puis-je détecter efficacement les doublons sur mon site web ?
Pour un diagnostic précis, nous vous recommandons d’utiliser des outils d’audit technique comme Screaming Frog ou Siteliner, qui scannent votre structure pour repérer les titres et textes identiques. La Google Search Console est également indispensable pour consulter le rapport de couverture et identifier les URLs que Google a décidé d’exclure au profit d’une autre version.
Pour la duplication externe, des solutions comme Copyscape ou Killduplicate permettent de surveiller si vos textes sont pillés par des sites tiers. Une simple recherche Google entre guillemets sur l’une de vos phrases clés peut aussi révéler des copies non autorisées.
Quelles solutions techniques permettent de résoudre les problèmes de duplication ?
La solution la plus efficace consiste à installer la balise canonical (rel= »canonical ») pour désigner officiellement la page « maître » aux yeux de Google. Si vous souhaitez fusionner deux contenus ou corriger des erreurs de migration (HTTP vers HTTPS), privilégiez la redirection 301, qui transfère l’autorité SEO vers la nouvelle URL.
Pour les pages techniques sans valeur ajoutée, comme les paniers d’achat ou les résultats de recherche interne, l’application d’une balise meta noindex est idéale. Elle permet de conserver ces pages accessibles pour vos utilisateurs tout en empêchant leur indexation inutile.
Comment protéger mon site e-commerce contre le contenu dupliqué ?
En e-commerce, la duplication provient souvent des fiches produits constructeur ou de la navigation à facettes (filtres de prix, taille, etc.). Nous vous conseillons de réécrire systématiquement les descriptions pour les rendre 100% uniques et d’utiliser des sélecteurs JavaScript pour regrouper les variantes de produits sur une seule URL.
Pensez également à configurer la gestion des paramètres dans la Search Console pour indiquer à Google quels éléments ignorer. Enfin, pour vos versions internationales, l’utilisation rigoureuse des balises hreflang est cruciale pour éviter que vos différentes versions linguistiques ne se parasitent entre elles.
L’intelligence artificielle augmente-t-elle les risques de contenu dupliqué ?
Absolument. L’essor de l’IA générative facilite la création massive de textes qui, bien que non identiques mot pour mot, présentent une similarité sémantique très élevée (near duplicate). Google affine sans cesse ses algorithmes pour valoriser la création humaine et l’expertise réelle.
Pour vous démarquer, misez sur votre signature éditoriale et intégrez des preuves d’expérience concrète (critères EEAT). Un contenu enrichi de vos propres tests, analyses et témoignages reste la meilleure protection contre la banalisation des textes générés automatiquement.
Besoin d'aide sur ce sujet ?
Nos experts auditent votre site et identifient vos meilleures opportunités de croissance. Gratuitement.
Demander mon audit gratuitExpert SEO chez GK Digital: agence SEO et GEO.